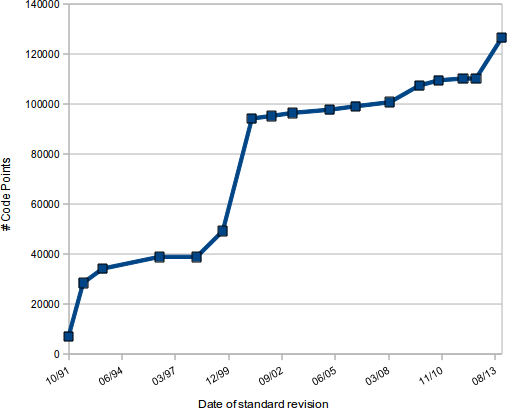
Unicode is organized in 17 planes with a total of 1,112,064 code points; of those, two planes (131,072 code points) are specified for private use, so future Unicode standards can assign a total of 980992. Almost 13% of these code points have a present or proposed use.
Unlike the allocation of internet addresses, it seems likely that the allocation of Unicode code points is likely to already be slowing down. On the other hand, there sure are a lot of code points in the pipeline, as evidenced by the large uptick at the end of the graph. Personally, I'd bet against actually exhausting Unicode in my lifetime, as long as it only includes terrestrial languages. If the aliens come to earth and we try to add their scripts to unicode, all bets are off.
Files currently attached to this page:
| growth-of-unicode.ods | 22.2kB |
Entry first conceived on 6 February 2013, 14:59 UTC, last modified on 3 October 2013, 13:13 UTC
Website Copyright © 2004-2024 Jeff Epler