More junkdrawer features
I've continued enhancing the static site generator for my junkdrawer (github gist / pastebin replacement). The source code for the static site generator lives right in the same repo.
One thing I missed was some kind of ability to preview PDFs that I have uploaded to the junkdrawer, such as this m6800 reference card that disappeared earlier this year from its original site.
Initially, I tried to directly show the PDF as an embed or object tag.
However, getting the embedded viewer properly sized was beyond what I wanted to tangle with.
Instead, I took the same approach github does: Convert the first pages of the pdf to images and display them with the img tag. This then gets the lightbox treatment from my mkdocs setup, so you can comfortably zoom the page image to its full 150dpi majesty.
I have made the decision to not worry too much about specially-crafted PDF files that might exploit bugs in poppler's pdftoppm: I'll have already locally viewed any PDF I'm putting in the junk drawer, so the Bad Thing will already have occurred. Anyway, the site generation process installs the latest packaged pdftoppm so I'm also likely to have patches for known poppler flaws.
The main downside I've identified is that the image is just an image and is therefore not searchable with the browser's search feature. Alas.
junkdrawer gets a grebedoc page
I added machinery to my junkdrawer repo so that it also builds a static website that's served by grebedoc.
The code to do it is in the junkdrawer's "site" directory and it functions just great using the free codeberg-tiny runner for CI.
Calling a Python function with a timeout
In Python 3.13+ with pyrepl, my rpn calculator can show the result of evaluating some code while the user is entering it at the prompt.
Most code is trivial (e.g., 3 4 5 * * to multiply some numbers together) but
complex code including recursion is possible. This can give code that runs for
quite a long time! It's one thing if this happens when you hit enter, but
another when there's the possibility that the repl freezes in the middle of
entering some code.
There are various recipes for running Python code with timeout, but I wrote my
own. Then, just for extra fun, I made it properly type check with ty.
I didn't integrate it into pydc yet but that part shouldn't be hard.
See the docstring of the function for some additional caveats.
(Embedded not available - View kvghgghs/timeout.py on codeberg.org or download raw)
Python multiline input: Using _pyrepl in your own code
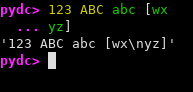
Colorized, multiline input in Python 3.14
Starting with Python 3.13, a new internal module called _pyrepl has been added to Python. It is used for the regular interactive prompt, and allows multiline editing. Python 3.14 adds syntax highlighting.
I thought these features would be great to use in my own program, an rpn calculator modeled after the classic unix dc.
Since _pyrepl is an internal module to Python, it's not intended for use by scripts. But, they can't stop us! Here's what I've learned...
Basics: Multiline editing
The dc language denotes strings with balanced square brackets, so that [x [a b] w] is a string. In terms of multiline editing, we want input to continue when there is an unbalanced open bracket character.
Here's a simplistic implementation of a function which checks some input to find out whether it's balanced:
def count_brackets(s):
return s.count("[") - s.count("]")
However, what we need is a true-or-false predicate. In Python zero is false and nonzero numbers are true so we could use count_brackets directly, but I also wrote an actual predicate:
def more_lines(s):
return count_brackets(s) > 0
Now, we can go ahead and do some multiline input:
from _pyrepl.readline import multiline_input
while True:
try:
statement = multiline_input(more_lines, ps1, ps2)
except EOFError:
break
print(repr(statement))
A session with this program might look like so:
pydc> 3 3 +
'3 3 +'
pydc> [a [
... b]
... c]
'[a [\nb]\nc]'
Advanced: Syntax colorization
From Python 3.14, the Python repl colorizes Python code. We can repurpose this for highlighting our own syntax rather than Python syntax.
In Python 3.14, it's necessary to monkey-patch the function _pyrepl.reader.gen_colors. In Python 3.16 alphas, that doesn't work. Instead, it is required to update the gen_colors property of the reader object. Happily, the same gen_colors routine works in the same way in each version.
gen_colors generates a sequence of ColorSpan objects. The span member is an inclusive range of characters, and the tag must be one of several predefined python syntax elements.
Rather than fully highlighting the dc language, I'll show a simple gen_colors implementation, which colors digits and uppercase letters the way pyrepl shows numbers, lowercase letters the way pyrepl shows strings, and everything else in the terminal default color:
if hasattr(_pyrepl.utils, 'ColorSpan'):
from _pyrepl.utils import ColorSpan, Span
import _pyrepl.readline
def gen_colors(s):
for i, c in enumerate(s):
if c in string.ascii_lowercase:
yield ColorSpan(Span(i, i), "string")
elif c in string.digits or c in string.ascii_uppercase:
yield ColorSpan(Span(i, i), "number")
else:
yield ColorSpan(Span(i, i), "reset")
reader = _pyrepl.readline._wrapper.get_reader()
if hasattr(reader, 'gen_colors'):
reader.gen_colors = gen_colors
else:
import _pyrepl.reader
_pyrepl.reader.gen_colors = gen_colors
It's worth noting that the builtin gen_colors also takes care to emit fewer spans whenever possible, something I ignored for this example.
Advanced II: Showing messages
Pyrepl includes support for an area below the entry area. This is for showing completions, but you can use it to show whatever you like.
This is done by monkeypatching the reader object's after_command:
reader = _pyrepl.readline._wrapper.get_reader()
original_after_command = reader.after_command
def after_command(self, cmd) -> None:
original_after_command(cmd)
if cmd.finish: return
buffer = "".join(self.buffer)
msg = repr(buffer)
if msg != self.msg:
self.msg = msg
self.dirty = True
reader.after_command = lambda cmd: after_command(reader, cmd) # fake instance method
This has the effect of continuously previewing what will be shown after hitting enter.
The code
Putting it all together, here's the full script:
(Embedded not available - View gz0bnruv/mli.py on codeberg.org or download raw)
The oldest bug I ever fixed? (no)
Correction
Update, 2026-05-24: It was an emulator bug. My friend tested on his hardware and the original comparison code works correctly.
Original post
I've been playing with Tom Pittman's Tiny BASIC for 6800 computers. It's a very simple, small, and early BASIC implementation. It is also almost as old as me, being announced by February 1976.
In this BASIC, all numbers are 16-bit signed integers with a range of -32768 to 32767 inclusive.
Anyway, while working in Tiny BASIC, I got some weird results and boiled it down to the following:
IF 32513 < 0 THEN PRINT "WAT"
This prints "WAT", even though we usually consider 32513 to be greater than 0.
After spending an evening and a morning with it, and comparing the implementation to Tom Pittman's Tiny BASIC for 6502 computers, I believe that this bug is in the original implementation, and not the emulator I'm using.
The original version performs a 16-bit subtraction from two separate 8-bit subtractions; then, from the final flags value tries to determine whether the full result of the subtraction is greater to, less than, or equal to zero.
This works for many inputs. However, for some particular input values, the CPU flags—which are only aware of the results of the most significant byte of the subtraction—don't match up with the usual notions of comparison.
The fix, which I've implemented in my version of Tiny BASIC, is to instead compare the MSBs first as signed numbers, then if they are equal, to compare the LSBs as unsigned numbers.
I also wrote a test harness which performs about 60,000 comparisons, checking them against Python's idea of integer ordering. Now, all those comparisons (as well as my original test case) pass.
From what I can determine, the listing I have is derived from "TINY BASIC 6800 V.3R (C)1976 BY TOM PITTMAN (TB683R)". The "3" indicates it's the 4th release (0-based version numbering); TB682R was mentioned in ddj in October, 1976.
I'm a bit tickled to think I have fixed a bug that someone wrote when I was less than 1 year old cough 50 years ago cough. It's a bit much to claim I might be the first person who ever noticed or fixed the bug, but I looked through a range of old dr dobb's journal issues and never found anyone who remarked on the bug.
This is quite possibly the earliest-written bug I will ever fix.
Having fun programming
I hear a lot about so-called vibe coding, in which you prompt an LLM to produce a bunch of code with little regard to the quality, so that you can get something that sort of works quickly.
While I'm not interested in that, I did decide to break with my recent practice and write some software with a lot less regard to trappings of quality. I did NOT:
- Make a pyproject.toml file
- Carefully install requirements with uv or pip
- Use ruff, pre-commit, ty, and other best practices
- Write any tests whatever
- Check license compatibility even once
Instead, I:
- Started typing into a blank Python file with no real plan
- Vendored in whatever files I wanted
- Called into a C library (6800 CPU simulator from SIMH) with ctypes instead of making a nice Pythonic API
- Well did I say C library? More like a C source file copied from somewhere else and edited until it could be built into a shared library.
- Then did it again with a speech synthesizer simulator from MAME
- Just let it grow organically
- Added whatever feature I wanted next, until it felt done
The result? A pretty usable emulator for a 6800-based breadboard computer. It not only emulates the computer, but provides its own readline-based debugging interface with debug symbols, instruction decoding, breakpoints, etc.
This project will never "grow into" anything big, nor is it supposed to, so whatever level of technical debt doesn't stop me progressing is absolutely fine!
It's felt in some ways more fun than trying to do a Quality Python Package I imagine putting on pypi...
radix40 encoding
I was inspired to design an original(?) text encoding for tiny embedded
computers. It is, however, similar to DEC RADIX 50 from 1965. (That's 50₈=40₁₀).
Since 40³<65536, it is possible to store 3 symbols in each 16 bit word.
In radix 40 you get the 26 basic alphabetic characters, 10 digits, and 4 additional symbols. I chose:
- End of string
- Space (ASCII 32)
- Exclamation point (ASCII 33)
- Double quote (ASCII 34)
The choice of 3 characters that are adjacent in ASCII saved code size on the decoder; initially I thought maybe "-" and "." would be useful choices.
Unlike RADIX 50, the encoding is arranged so that no division or remainder operation is needed. Instead, at each step of decoding, a 24 bit temporary value is multiplied by 40 and the top byte gives the output code. In the assembler vesion, the multiplication is coded as x<-x*8; tmp<-x; x<-x*4; x<=x+tmp) since the MC6800 has no multiply instruction.
Here are the not quite matching Python encoder
(Embedded not available - View epvenhla/b40.py on codeberg.org or download raw)
And decoder/test program in m6800 assembly:(Embedded not available - View epvenhla/b40.asm on codeberg.org or download raw)
The implementation costs 90 bytes of code and 6 bytes of zero-page (which can be used for other purposes when the routine is not running). I estimate you'd need somewhat above 320 characters of text in your program for it to be a benefit.
The m6800 decoder can over-read the data by 1 byte, which seldom poses a problem in such environments.
By the way, this post debuts improved code embeds from forgejo. On my end, I just have to write [junk epvenhla/b40.py [lang python]] and the blog renderer does the rest!
"interlz5" in Python -- Apple II text adventure adventures
On the socials, someone asked whether anyone knew where the source for a tool called "interlz5" lived; they had found a binary but not the original (presumably C or C++) source. (Update: S. V. Nickolas's source code was right in front of us this whole time, a nested zip inside apple_ii_inform_demo_files.zip and now attached here as well)
This tool is described in An Apple II Build Chain for Inform by Michael Sternberg.
Depending on the game, it is stored as 1 or 2 sides of a disk. The first side consists of the interpreter (16KiB) followed by up to 98.5KiB of the story. The second side consists of the remaining story, up to 157KiB.
Since I could run the original "interlz5" tool, I was able to confirm what it did: It copies the interpreter binary as-is, then re-arranges the first part of the story according to an "interleave" rule. If the game is a small one, that's all and you're done! (well, you need to save it as a ".do" file or your emulator may perform a second interleaving step on the data!)
Now, are you ready for the surprise? As Sternberg wrote, "If the story file is larger than 100,864 bytes, the remainder of the Z-code is stored on a second 18-sector disk image." interlz5 writes this as a "nib" format file with no header.
Why 100,864 bytes aka 98.5KiB? This appears to be how much can be loaded into the RAM of a 128KiB Apple IIe while leaving room for the interpreter & other required structures. Why is the special format only used on "side b"? Since there is already always spare space on "side a", no special encoding was needed. However, one does wonder whether the initial load time was better with the interleaved 16 sector tracks compared to if they had used the "18-sector" format.
Oh, but what exactly is the format? Sternberg's document doesn't contain any detail, and at the time I didn't have S. V. Nickolas's interlz5 source to refer to.
I'm aware that 18-sector tracks were used by some other games (The term RWTS18 comes up) but there seem to be multiple different forms. In the case of these Z5 disks, each track is actually one big sector containing 4608 bytes of useful data encoded like so:
- The special sequence "d5 aa ad"
- The 0-based track number encoded as two bytes of gcr4
- 18 groups of 343 "gcr6" nibbles, organized just like a 256-byte sector
- Padding with "ff" flux patterns to the end of the track
The main reason that more data can be stored is because the extra space between sectors is removed. This lets 18×256 bytes be stored instead of just 16×256 bytes. This is inconvenient if the disk were to be written, because you'd have to rewrite the whole track. But in normal use, the game disk is read-only.
The groups of 343 "gcr6" nibbles all decode to 256 bytes exactly as the standard disk encoding, with the first 86 bytes encoding the two least significant bits of each byte and the remaining 256 bytes encoding the high 6 bits. Just like normal sector encoding, there's a byte sometimes called the "checksum" that is initialized to 0 and xor'd with the outgoing value before the gcr table lookup. The last gcr6 nibble is the final checksum value. This checksum is reset to 0 at each 256-byte boundary.
My program produces nearly the same output as interlz5, except for differences that I think stem from use of undefined data in the original compiled version. This means my files are not bit-for-bit identical. There are two specific causes:
- If the input z5 file does not exactly fill a track, interlz5 appears to fill with uninitialized value; I fill with zeros
- Two bits in each "twobit" area are unused. interlz5 appears to use a value from the first byte of the next sector, or an uninitialized byte at the end of data. I use the next byte if one exists, otherwise zero.
Due to the xor/checksum feature, any difference in data being encoded actually affects a subsequent gcr byte as well.
Compatibility? I had success with a specific pair of files:
9bec6046eca15a720a40e56522fef7624124b54e871b0a31ff9d5f754155ef00 interp.bin 6179b5d5b17d692ec83fe64101ff8e4092390166c2b05063e7310eb976b93ea0 Advent.z5With files output by either tool, I could successfully boot the game in AppleWin and go NORTH into the forest.
Sadly, I did not have luck with Hitchhiker's Guide or Beyond Zork ".z5" files I obtained from the internet, with either tool.
interl5.py is licensed GPL-3.0 and is tested with Python 3.13. It requires no packages outside the Python standard library. I have no plans to further develop it.
Files currently attached to this page:
| Advent.z5 | 135.0kB |
| apple_ii_inform2.pdf | 763.3kB |
| interl5.py | 3.5kB |
| interlz5-001.zip | 33.9kB |
| interp.bin | 16.0kB |
Junk drawer & embedding
Thick As A Brick / St Cleve Crossword solution
Migrating from github to codeberg: existing readthedocs projects
Variations on 'if TYPE_CHECKING'
Dear Julian
Mutual Tail Recursion in Python, fully mypy-strict type checked
Enabling markdown
Talking directly to in-process tcl/tk
All older entries
Website Copyright © 2004-2024 Jeff Epler